源地址
arXiv:1712.07465: Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition
简介
识别图像中的多个标签是计算机视觉中的一项基本但具有挑战性的任务。针对现有方法计算成本高、不能有效利用空间上下文的问题,论文提出了循环迭代的结合注意力机制的强化学习框架,并进行了对应的熔断测试。
框架结构
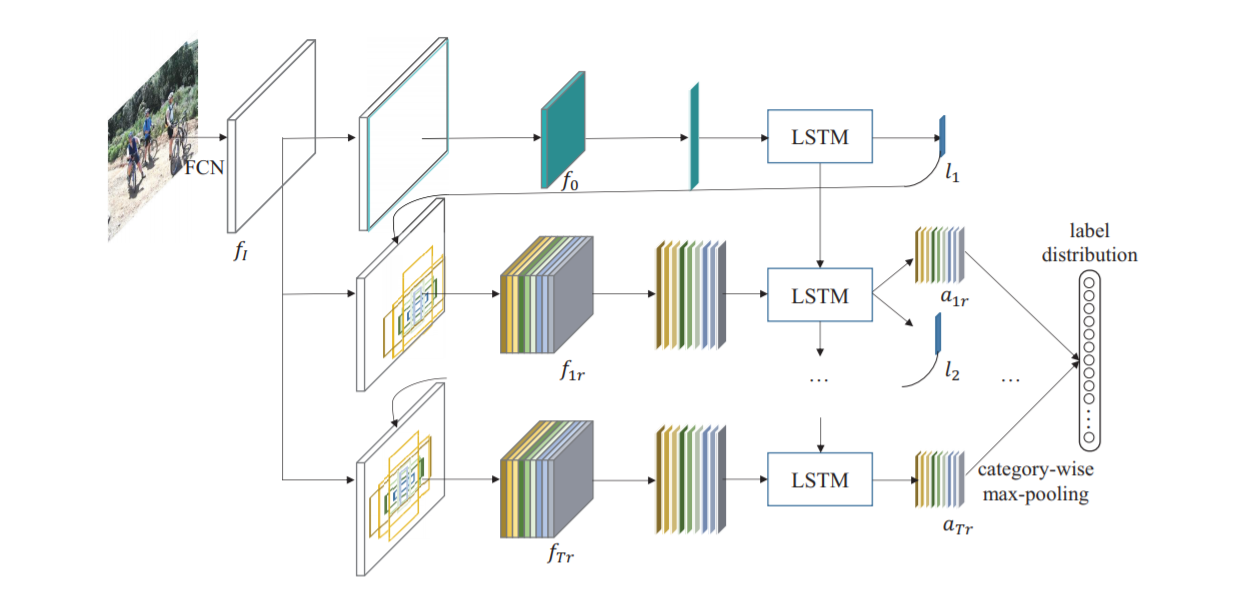
输入部分
将图片放缩至W*H的大小,送入FCN(VGG16 ConvNet)产生特征图\(f_I\)。
循环注意力感知模块
第t次迭代,模块首先接收在前一次迭代中计算的位置\(l_t\),并基于\(l_t\)按照不同的区域大小、不同的长宽比,提取k个区域\(R_t=\{R_{tr}\}^k_{r=1}\),然后从\(f_I\)中提取这些区域的特征,得到\(f_{tr} = G(f_i, R_{tr}) r=1,2,\cdots,k\)。
接下来,将特征送入LSTM网络实现的循环注意感知模块,将前一次迭代的隐藏状态以及当前定位区域的特征作为输入,得到每一个区域的得分\(\{a_{t1},a_{t2},\cdots,a_{tk}\}\)并搜索下一次迭代的最佳位置\(l_{k+1}\)。初始区域设置为整个图像,因此\(R_0\)只有一个区域,它仅用于确定的位置。
重复T+1次迭代,产生\(T \cdot k\)个得分向量,分别在每个类别中选出最大的得分向量,即
\[ a^c = \max(a^c_{11},a^c_{12},\cdots, a^c_{Tk}),c = 0,1, \cdots,C-1\]
训练过程
在形式上,模型需要学习策略\(\pi ((a_t,l_t+1)| S_t;\theta)\),该策略基于过去观察的序列和代理所采取的动作(即)来预测当前迭代的动作分布。为此,我们定义目标函数以最大化期望奖励,表示为:
\[J(\theta) = E_{P(S_T;\theta)}[R]\]
\[\nabla J(\theta) = \sum ^{T}_{t=1} E_{P(S_T;\theta)}[\nabla_{\theta}log\pi ((a_t,l_t+1)| S_t;\theta)R]\]
其中,\(R\) 为奖励函数,通过比对实际标签获得,即
在每一个时间 t,主体接收到一个观测 \(o_t\),通常其中包含奖励 \(r_t\)。然后,它从允许的集合中选择一个动作 \(a_{t}\),然后送出到环境中去。环境则变化到一个新的状态 \(s_{t+1}\),然后决定了和这个变化\((s_t,a_t,s_{t+1}\)相关联的奖励 \(r_{t+1}\)。强化学习主体的目标,是得到尽可能多的奖励。主体选择的动作是其历史的函数,它也可以选择随机的动作。
环境:\(s_t\), 即\(\{f_{t1}, f_{t2}, \cdots, f_{tk}, h_{t-1}\}\)
行动:
进行分类
分类有分类网络实现,并且有一个额外的损失函数(预测概率向量和真实概率向量的平均平方差)
寻找下一次\(l_{k+1}\)的最佳位置
由loc网络给出值作为一个位置的高斯分布的均值,高斯分布的方差则由经验给出。之后在高斯分布上随机取值。
奖励:
\[ r_t=\left\{ \begin{aligned} \frac{|g\cap p|}{n}& \quad t=T\\ 0 &\quad t<T\\ \end{aligned} \right. \]
\[R=\sum^T_{t=1}\gamma^{t-1}r_t\]
细节
输入部分
训练期间,所有样本图像的大小会调整为N*N,并随机裁剪为五个\((N-64)(N-64)\)的图像片段,同时对五个片段进行水平翻转,产生十个视图。最终结果为十个视图预测向量的平均值。
在实验中,生成整张特征图,并相应地为每个patch裁剪特征图,有效地减少了计算量。
在实验中,k设置为9个,通过三个尺度区域和三个宽高比产生。从而能够对更多种类的图像进行实验。
循环注意力感知模块
在特征图上进行裁剪操作,相比先前在原始输入图像处裁剪区域并应用CNN以重复提取每个区域的特征,避免了重复计算。
LSTM相关
长短期记忆网络(Long Short Term Memory networks) 设计 LSTMs 主要是为了避长时期依赖 (long-term dependency )的问题。
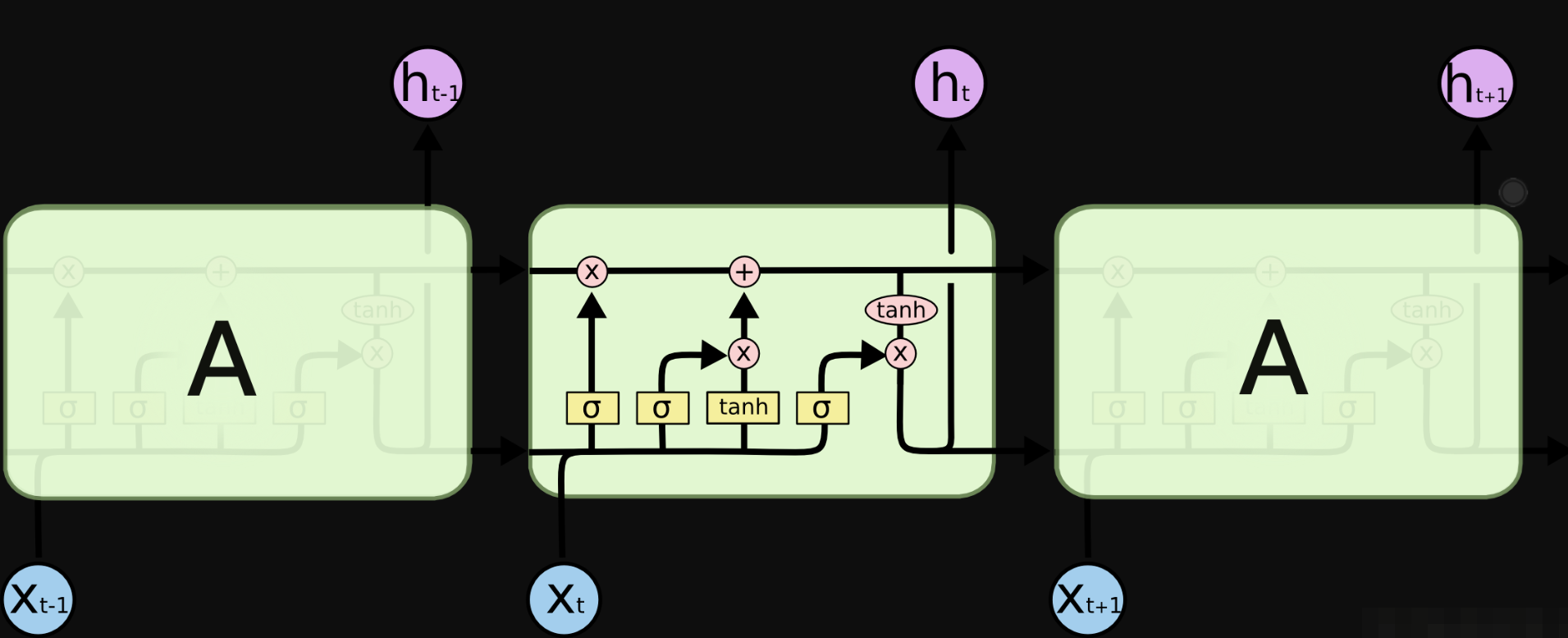
LSTM通过隐藏层状态进行遗忘、传入和输出。
消融研究
An ablation study typically refers to removing some “feature” of the model or algorithm, and seeing how that affects performance.
论文设计实验分析了关注区域、LSTM、可变比例和纵横比的区域、迭代次数对效果的影响,以仔细评估和讨论模型的关键组成部分的贡献。
一些想法
随机裁剪和翻转是图像集扩充的常见方法,可以提高样本数量,从而更好地进行训练。一般来说,还可以通过加入噪声,改变对比度、清晰度,甚至是采用GAN生成数据。
不同的尺度区域和不同的宽高比能够让模型更好地对物体进行检测,个人猜测即使在考虑成回归问题的时候也能够发挥不错的效果。
个人理解,LSTM网络通过模仿人类选择性记忆的机制,改善了RNNs持续记忆的问题,即长文本等应用场景下RNNs需要过多样本和迭代次数来寻找合适的映射关系的问题。
感觉上,LSTM的遗忘机制和ResNet的跨层连接有一些相同的点。
消融研究能够有效地体现模型的优势,减少其他不确定因素的影响。和精心设计的图表一起,可以更好地实现对模型的展示。